The Power of Moving LLM Reasoning into Latent Space
There are plenty of tasks that the large LLMs we use every day are still terrible at. One category: simple puzzles that require generalizing from limited examples, interpreting symbolic meaning, and flexibly applying rules, like those in the ARC-AGI benchmarks. These problems are dead-simple for humans to solve.
Sudokus fall into this category as well. Humans breeze through them, but they’re brutally hard (or sloooow to solve) for LLMs.
Think about how an LLM like ChatGPT might solve a Sudoku: “Cell 3,4 can’t be 5 because row 3 has 5, can’t be 7 because column 4 has 7…” writing out every single logical step as text. This is both error-prone (one wrong token derails everything) and incredibly slow and token-inefficient.
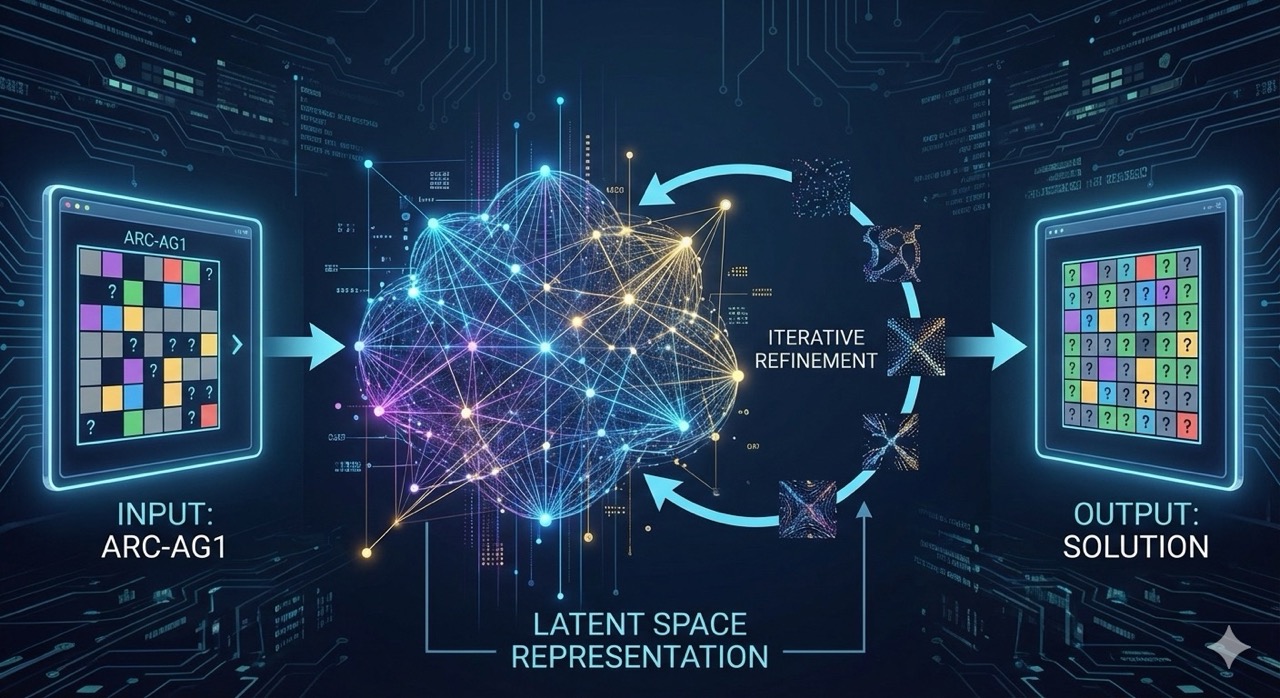
I just read “Less is More: Recursive Reasoning with Tiny Networks”, which builds on the Hierarchical Reasoning Model (HRM) from last summer that generated lots of attention. The result: a 7M parameter model achieves 87% accuracy on extreme Sudokus and 45% on ARC-AGI-1.
For comparison, that’s 0.01% the size of DeepSeek R1 (671B parameters), which has a 0% solve rate on Sudokus and 15.8% on ARC-AGI-2. Similar story when comparing against Claude or OpenAI models.
That’s a breathtaking difference. I’m still feeling surprised.
The big innovation isn’t better training data, better post-training, better mixture of experts setup, etc.
It’s a fundamentally different model architecture. Reasoning happens in a latent space rather than through text. The model maintains a compressed internal state and iteratively refines it (“thinking” without generating a single token). This makes the models orders of magnitude smaller while dramatically outperforming their giant cousins on these tasks.
I predict we’ll see tiny architectures like this get a lot of attention and become useful/impactful in industry settings as researchers look to make today’s massive LLMs much smaller while preserving (or improving) their ability to reason through specific problem types.